[pandas] merge/concat data-frame
Sometimes, two data set should be merged to provide more accurate information.
Merging data frame is divided into two parts: vertical and horizontal merging.
1) Vertical merging
import pandas as pd
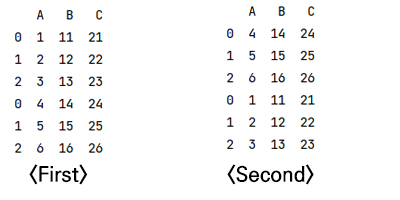
df1 = pd.DataFrame({'A' : [1, 2, 3], 'B' : [11, 12, 13], 'C' : [21, 22, 23]})
df2 = pd.DataFrame({'A' : [4, 5, 6], 'B' : [14, 15, 16], 'C' : [24, 25, 26]})
print(df.concat([df1, df2]))
print(df.concat([df1, df2]))as you can see the result, depending on the order of the dataframe, the order of the data merged varies.
# after merging, index has not been reset.
# therefore, we need to reset the index.
# this time, rather than using reset, we use 'ignore_index=True'
print(pd.concat([df1, df2], ignore_index=True)What if the order of the field (order of the column) differs?
# it doesn't matter. The program will automatically align the column.
# what if there is no value for that field (column) to the other data frame?
# Still show the result while the data frame that has no value for that field will be shown as
# missing value ('NaN')
print(pd.concat([df1, df2], ignore_index=True))Concept of outer and inner
- Outer: it would be easier to conceptualize as 'union'
- Inner: it would be easier to think as 'intersection'
Basically when the user try to concatenate two data frame, the program will automatically concatenate the two by using the concept of union. Thus, to use the concept of intersection, you should notify as 'join='inner'
# outer - union
# the following two codes will return the same result
print(pd.concat([df1, df2], ignore_index=True))
print(pd.concat([df1, df2], ignore_index=True, join='outer'))
# inner - intersection
print(pd.concat([df1, df2], ignore_index=True, join='inner'))
2) Horizontal merging
df1 = pd.DataFrame({'A' : [1, 2, 3], 'B' : [11, 12, 13], 'C' : [21, 22, 23], 'D' : [31, 32, 33]})
df2 = pd.DataFrame({'E' : [3, 4, 5], 'F' : [13, 14, 15], 'G' : [23, 24, 25], 'H' : [41, 42, 43]})
# in this time, we cannot use 'ignore_index=True'
# because it would delete the index info ('A', 'B', etc)
# plus, as it is combined horizontally, it should add 'axis=1'
print(pd.concat([df1, df2], axis=1)Another example
df1 = pd.DataFrame({'ID' : [1, 2, 3, 4, 5], 'Gender' : ['F', 'M', 'F', 'M', 'F'],
'Age' : [20, 30, 40, 25, 42]})
df2 = pd.DataFrame({'ID' : [3, 4, 5, 6, 7], 'Height' : [160.5, 170.3, 180.1, 142.3, 153.7],
'Weight' : [45.1, 50.3, 72.1, 38, 42]})
print(pd.concat([df1, df2], axis=1))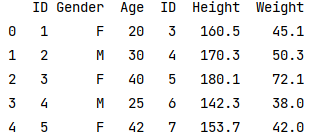
As ID does not match between df1 and df2, we need to know a new concept - left, right, inner, and outer join.
# if you want to check height and weight among gender and age is confirmed.
print(pd.merge(df1, df2, how='left', on='ID')
# or
print(pd.merge(df2, df1, how='right', on='ID')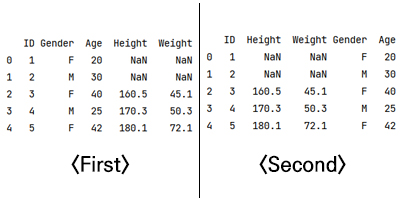
As you can see the result, even though the order of the column differs, what the data shows are same.
* left / right is determined by where the main data frame the user would like to use.
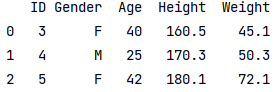
# if the user want to confirm the whole thing - gender, age, height, and weight
print(pd.merge(df1, df2, how='inner', on='ID'))
Another example: if the ID is different, so that we need to provide the information to the program that they have different column, but same function.
df1 = pd.DataFrame({'USER_ID' : [1, 2, 3, 4, 5], 'Gender' : ['F', 'M', 'F', 'M', 'F'],
'Age' : [20, 30, 40, 25, 42]})
df2 = pd.DataFrame({'ID' : [3, 4, 5, 6, 7], 'Height' : [160.5, 170.3, 180.1, 142.3, 153.7],
'Weight' : [45.1, 50.3, 72.1, 38, 42]})
# outer: can be easily considered as "union"
print(pd.merge(df1, df2, how='outer', left_on='USER_ID', right_on='ID))