-
[pandas] Missing valueRoad to Data Analyst/Python 2023. 1. 18. 10:30
Table of contents
0) Intro
1) Check the dataset whether it has any missing value
2) Delete the row / column that has any missing value
3) Replace the missing value with other neighboring value / average
0) Intro
In the dataset, it is likely to have some missing values. To analyze the data, it is important to decide how to cope with this missing value.
To make an example, we need NumPy.
import pandas as pd import numpy as np df = pd.DataFrame({'a': [1,1,3,4,5], 'b': [2,3, np.nan, 3,4], 'c': [3,4,7,6,4]})1) Check the dataset whether it has any missing value
# (1) print(df.isnull()) # (2) print(df.isnull().sum())
(1): return True where the value is missing (np.nan)
(2): return summary of total number of missing value in each column
2) Delete the row / column that has any missing value
# delete the row df.dropna(inplace=True) print(df) # delete the column df.dropna(axis=1, inplace=True) print(df) # as the index information has not reset we can use reset to make the dataset clear. df.reset_index(drop=True, inplace=True)* delete the column: axis=1 represents the column instead of row
3) Replace the missing value with other neighboring value / average
# replace missing values with a certain value df.fillna(0, inplace=True) print(df)* the place where 0 is written, the character (integer/float type is also available) can be written as well.
df = pd.DataFrame({'a': [1,1,3,4,np.nan], 'b': [2,3, np.nan, np.nan,4], 'c': [np.nan, 4,1,1,4]}) # (1) replace the missing value with the next row df.fillna(method='bfill', inplace=True) print(df) # (2) replace the missing value with the previous row df.fillna(method='ffill', inplace=True) print(df)
As you can see the result of (1) and (2), when there is also a missing value at the next row or the previous row, the program will reach out to the one after the row (ffill) or the one before the row (bfill) until the program finds one. After the it found any value, it replaces the missing value with that value.
As you can see the result of (1) at column 'a' fifth row, as there is no value after the fifth row, it cannot replace the missing value.
Users can limit the range that the program can replace the missing values.
df.fillna(method = 'ffill', limit = 1, inplace = True) print(df)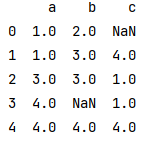
As you can see row 3, column 'b' and row 0 cannot replace the missing value because the limit is only 1 (so that the missing value cannot reach out to 3.0)
Users can replace the missing value with the average
# replace the missing value with the average of each column value df.fillna(df.mean(), inplace=True) print(df) # replace the missing value with the average of a certain column value df.fillna(df.mean()['a'], inplace=True) print(df) # replace the missing value of a certain column with the average of each column value df.fillna(df.mean()[['a', 'c']], inplace=True) print(df)'Road to Data Analyst > Python' 카테고리의 다른 글
[pandas] add new column / delete column (0) 2023.01.21 [pandas] Data type conversion (astype etc...) (0) 2023.01.21 [pandas] Sort (0) 2023.01.18 [pandas] value_counts() 특정변수 least occurrence로 정렬하기 (0) 2022.09.24 [NumPy] np.ceil(), np.copysign(), np.intersect1d() (0) 2022.09.12