-
[pandas] agg() & sort_values() - 데이터셋에서 가장 많이 팔린 상품 찾기Road to Data Analyst/Python 2022. 9. 12. 16:59

출처 : https://rfriend.tistory.com/392 위 그림처럼 pandas에서 데이터를 groupby를 통해 원하는 데이터 셋을 가져온 후, 그 데이터들을 count, mean과 같은 값으로 가공 가능하다.
그 method/function을 하나만 사용하고 싶다면, groupby(['column name #1', 'column name #2']).mean()과 같이
여러개의 method/function를 사용하고 싶다면 groupby(['column name #1', 'column name #2']).agg('mean', 'sum')처럼 사용해야 한다.
Practice

출처 :https://github.com/guipsamora/pandas_exercises 이 데이터 셋에서 가장 많이 팔린 (in terms of quantity) 상품(item_name)을 구하려고 한다면,
다음과 같은 데이터 groupby, agg()가 필요하다.
import pandas as pd url = '데이터 가져올 링크 삽입' df = read_csv(url, '\t') chipo = df item_quants = chipo.groupby(['item_name']).agg({'quantity':'sum'}) item_quants.sort_values('quantity', ascending=False)[:5](1) chipo의 groupby를 통한 item_name 지정,
(2) 그 중 동일 상품끼리의 quantity를 sum한다는 agg({'quantity':'sum'})를 사용하여 데이터를 집계
(3) 집계된 quantity를 ascending이 아닌, descending으로 정렬 (by sort_values())
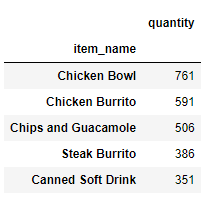
출처 https://github.com/guipsamora/pandas_exercises 위 그림처럼, 내림차순, 가장 많은 순서대로 quantity와 item_name이 집계된 것을 알 수 있다.
'Road to Data Analyst > Python' 카테고리의 다른 글
[NumPy] np.ceil(), np.copysign(), np.intersect1d() (0) 2022.09.12 [pandas] str.slice() & lambda - 데이터셋에서 맨 앞에 있는 화폐단위 삭제 및 float로 변환 (0) 2022.09.12 [NumPy] Problem set (0) 2022.06.13 [NumPy] Fancy Indexing 팬시 인덱싱 (0) 2022.06.13 [Project Euler] Q7. 10001st prime (0) 2022.06.13